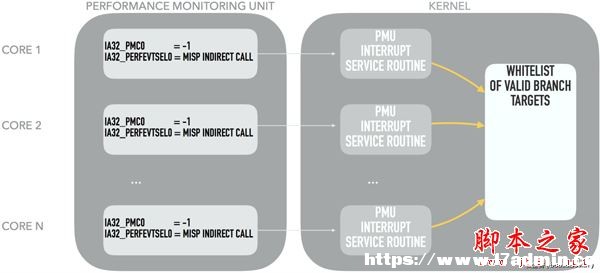
Rop是借鑒淘寶開發平臺實現的全功能Rest Web Service 開源框架,提供了請求/響應序列化、數據檢驗、會話管理、安全管理等高級主題的東西。 前言 隨著漏洞緩解技術的不斷發展,常用的一些漏洞利用手段如ROP變得越來越困難,來自ENDGAME的Cody Pierce發表了一篇[博客],稱ROP的末日已經來臨,新的漏洞緩解技術將有效應對未知的漏洞威脅,并宣布他們實現了一種全新利用硬件輔助的控制流完整性的防御機制——HA-CFI。 不過這種論調向來是要打自己臉的,因為總有新的漏洞利用方式出爐,永遠不能低估黑客的想象力。比如Flash推出的一系列漏洞緩解機制中仍然存在漏洞,這就很尷尬了(CVE-2016-4249,詳情可參考古河在HitCon上的演講)。 知己知彼,百戰不殆。只有充分了解新的漏洞緩解機制,才能有更好的思路去繞過,才能對未來發展新的防御機制更有啟發。 控制流完整性 控制流完整性(Control Flow Integrity, CFI)是由加州大學和微軟公司于2005年提出的一種防御控制流劫持攻擊的安全機制。通過監視程序運行過程中的控制流轉移過程,使其始終處于原有控制流圖所限定的合法范圍內。 具體的做法是分析程序的控制流圖,重點關注間接轉移指令,如間接跳轉、間接調用和函數返回等指令,獲取相應的白名單。在程序運行過程中對間接轉移指令的目標進行檢查核對,而攻擊者對控制流的劫持會導致目標不在白名單中,此時CFI可迅速進行阻斷,保證系統安全。 一般來說,控制流完整性可分為細粒度和粗粒度兩種實現方式。細粒度CFI嚴格檢查每一個間接轉移指令的轉移目標,但會嚴重影響程序的執行效率;粗粒度CFI將一組或相近類型的目標歸到一起進行檢查,可在一定程度上降低開銷,但會使安全性降低。 基于硬件的CFI 早期一些CFI思路是基于二進制插樁的,最簡單粗暴的方式是在每條控制流轉移指令前插入檢驗代碼,判斷目標地址的合法性。但這種方式的開銷實在太大,難以在實際中部署。因此研究人員提出的一些改進方法均在效率上進行了妥協,放寬了檢查條件。實質上都是粗粒度的CFI,實際效果會打折扣,可被攻擊者利用繞過。 既然CFI受制于效率,那么是否可以引入硬件機制來提高效率呢?畢竟相比二進制插樁的方式,硬件的開銷幾乎是可以忽略的,但前提是我們必須找到可行的實施方案。這就需要對處理器平臺上的一些技術細節有所了解。 Intel為了讓用戶能夠更好的對應用程序的性能進行優化,提供了一系列輔助調試的硬件支持,這里著重介紹LBR(Last Branch Record)、BTS(Branch Trace Store)和PMU(Performance Monitoring Unit),早期的一些研究都是在這些基礎上開展的。 LBR LBR是Intel提供的一組用于記錄和追蹤程序最近的若干次跳轉信息的循環寄存器組,這些寄存器的數量與Intel處理器的微架構相關,在早幾年的Haswell架構中有16個這樣的寄存器,也就是說可以記錄程序最近的16條跳轉指令的信息(包括從哪跳轉過來的,將要跳轉到哪去),而在最新的Skylake架構中有32個。LBR寄存器的強大之處在于其定制性很強,能夠過濾掉一些不重要的跳轉指令,而保留需要重點關注的跳轉指令。 BTS BTS是另一個用于記錄程序分支信息的功能單元,但與LBR不同的是,BTS不會將程序的跳轉指令信息存儲到寄存器中,而是將其存儲至CAR(cache-as-RAM)中或是系統的DRAM中,這里就沒有條數的限制了,只要空間足夠,BTS可以存儲大量跳轉指令的信息。 但另一方面,BTS的時間開銷要比LBR高出許多。 PMU PMU是Intel引入的用于記錄處理器事件的功能單元。PMU事件有好幾百個,非常詳盡,包含了處理器在運行過程中可能遇到的所有情形,例如指令計數、浮點運算指令計數、L2緩存未命中的時鐘周期等。當然其中也有一個在HA-CFI中非常有用的事件,分支預測失敗事件。 HA-CFI基本思路 如果大家對計算機體系結構稍有了解就會知道,現代處理器都是采用流水線的方式執行指令,而分支預測是保證其高效的一個非常重要的技術。 當包含流水線技術的處理器處理分支指令時會遇到一個問題,根據判定條件的真/假的不同,有可能會產生轉跳,而這會打斷流水線中指令的處理,因為處理器無法確定該指令的下一條指令。流水線越長,處理器等待的時間便越長,因為它必須等待分支指令處理完畢,才能確定下一條進入流水線的指令。分支預測就是預測一條可能的分支,讓處理器沿著這條分支流水執行下去而不用等待。若預測成功,那么皆大歡喜,處理器繼續執行下去即可;若預測失敗,處理器則需要回退到分支位置,重新沿著正確的分支方向執行。 分支預測有許多種策略,如靜態預測和動態預測等,當然學術界還有很多其他非常高端的方法。但無論采用何種方式進行分支預測,攻擊者劫持指令流后,其目標地址顯然不是處理器能夠預測到的,必然會產生一個分支預測失敗的PMU事件,這相當于一個預警信息,接下來要做的就是從這類PMU事件中甄別出哪些是正常的分支預測失敗,哪些是由于攻擊者劫持指令流造成的分支預測失敗。 僅僅預警是不夠的,HA-CFI還希望能夠準確定位指令流被劫持的位置,并及時進行阻斷。此時PMU就幫不上什么忙了,因為PMU只負責報告處理器事件,而不記錄產生該事件的具體指令。當某一時刻PMU報告一個分支預測失敗的事件時,此時的指令指針可能早已越過了跳轉指令,很難回溯定位發生分支預測失敗的指令位置。 因此,為了精確定位造成分支預測失敗的指令,還需要借助LBR的幫助。當分支預測失敗的PMU事件觸發中斷服務程序(ISR, Interrupt Service Routines)時,ISR將從LBR中取出最新的若干條間接跳轉指令,其中必然包含造成分支預測失敗的間接跳轉指令。而且LBR中還記錄了更為詳細的信息,可方便ISR核對該間接跳轉指令的目標地址是否在白名單中。若跳轉指令的目標不在白名單之中,說明指令流可能遭到劫持,可及時阻斷。示意圖如下所示:
HA-CFI示意圖 此外,為了進一步保證HA-CFI的效率,可以根據當前進程的重要性選擇性的開啟或關閉PMU,如當前進程為IE或Firefox瀏覽器時,開啟PMU;若當前進程為Calc.exe這樣不太容易遭受攻擊的進程,則關閉PMU,如圖所示:
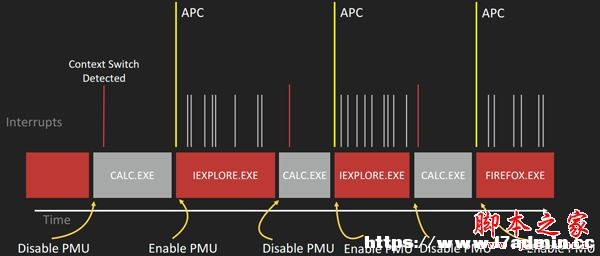
選擇性開啟PMU 效果與展望 Cody Pierce等人選取了多個經典的CVE漏洞,與EMET進行了比較:
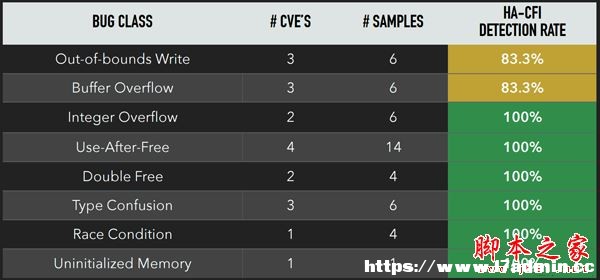
實驗結果1
實驗結果2 可以肯定的是,隨著對抗的不斷升級,未來漏洞利用的門檻將越來越高,與防御機制斗法也將也成為常態。 除了剛才提到的微軟的EMET,Intel在今年6月發布了一份關于CET的技術前瞻:[Control-flow Enforcement Technology Preview],準備從硬件層面入手防止ROP和JOP攻擊。通過引入一個shadow stack(類似的[想法]幾年前也有人提出),專門用于存儲返回地址,每當發生函數調用時,除了向當前線程棧內壓入返回地址,還要向shadow stack中壓入返回地址。返回時需要檢查線程棧中的返回地址是否與shadow stack中一致,若不一致,說明線程棧可能遭到攻擊者破壞,程序中止。此外,shadow stack處于層層嚴密防護之中,普通代碼是無法修改shadow stack的,除非攻擊者能控制內核,當然這并非不可能,只是攻擊門檻變得很高了。 CET目前仍是一個前瞻性的技術,距離真正實現還需要時間。即使實現了,也不意味著高枕無憂,HA-CFI也是如此,總有能繞過的方法,總有其未考慮到的情況,甚至可能它本身也存在著缺陷。 |
免責聲明:本站部分文章和圖片均來自用戶投稿和網絡收集,旨在傳播知識,文章和圖片版權歸原作者及原出處所有,僅供學習與參考,請勿用于商業用途,如果損害了您的權利,請聯系我們及時修正或刪除。謝謝!

始終以前瞻性的眼光聚焦站長、創業、互聯網等領域,為您提供最新最全的互聯網資訊,幫助站長轉型升級,為互聯網創業者提供更加優質的創業信息和品牌營銷服務,與站長一起進步!讓互聯網創業者不再孤獨!
掃一掃,關注站長網微信
 大家都在看
大家都在看